GCP VM disk loss
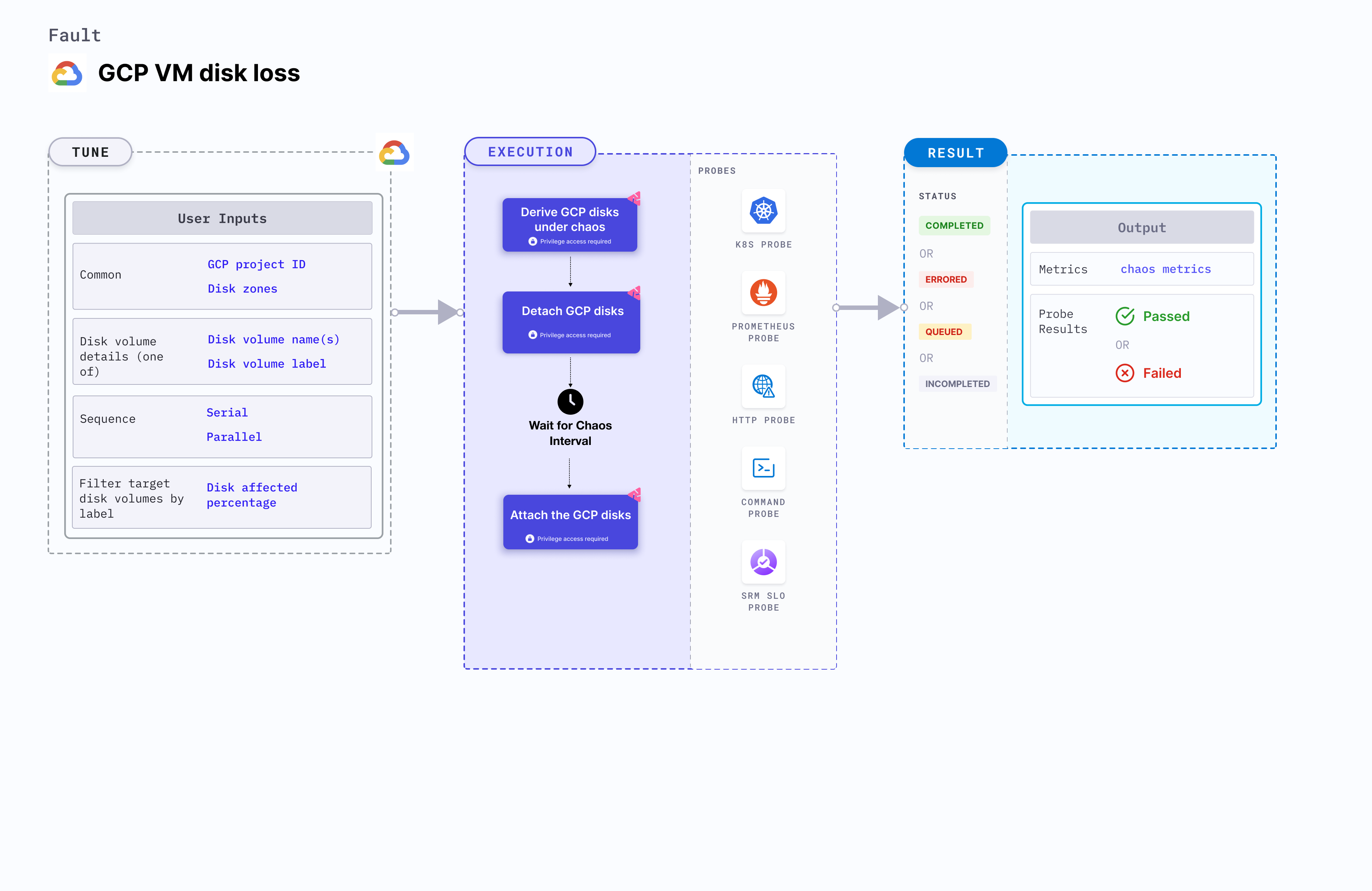
GCP VM disk loss disrupts the state of GCP persistent disk volume using the disk name by detaching the disk volume from its VM instance for a specific duration.
Use cases
- GCP VM disk loss fault determines the resilience of the GKE infrastructure. It helps determine how quickly a node can recover when a persistent disk volume is detached from the VM instance associated with it.
note
- Kubernetes > 1.16 is required to execute this fault.
- Service account should have editor access (or owner access) to the GCP project.
- Target disk volume should not be a boot disk of any VM instance.
- Disk volumes with the target label should be attached to their respective instances.
- Kubernetes secret should have the GCP service account credentials in the default namespace. Refer generate the necessary credentials in order to authenticate your identity with the Google Cloud Platform (GCP) docs for more information.
apiVersion: v1
kind: Secret
metadata:
name: cloud-secret
type: Opaque
stringData:
type:
project_id:
private_key_id:
private_key:
client_email:
client_id:
auth_uri:
token_uri:
auth_provider_x509_cert_url:
client_x509_cert_url:
Fault tunables
Mandatory fields
| Variables | Description | Notes |
|---|---|---|
| GCP_PROJECT_ID | Id of the GCP project containing the disk volumes. | All the target disk volumes should belong to a single GCP project. For more information, go to GCP project ID. |
| DISK_VOLUME_NAMES | Names of the target non-boot persistent disk volume. | Multiple disk volume names can be provided as disk1,disk2,.. and so on. For more information, go to detach volume by names. |
| ZONES | The zone of the target disk volumes. | Only one zone is provided, which indicates that all target disks should reside in the same zone. For more information, go to zones. |
Optional fields
| Variables | Description | Notes |
|---|---|---|
| TOTAL_CHAOS_DURATION | Duration that you specify, through which chaos is injected into the target resource (in seconds). | Defaults to 30s. For more information, go to duration of the chaos. |
| CHAOS_INTERVAL | Time interval between two successive chaos iterations (in seconds). | Defaults to 30s. For more information, go to chaos interval. |
| SEQUENCE | Sequence of chaos execution for multiple target disks. | Defaults to parallel. It supports serial sequence as well. For more information, go to sequence of chaos execution. |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30s. For more information, go to ramp time. |
Detach volumes by names
It specifies a comma-separated list of volume names that are subject to disk loss. This fault detaches all the disks with the given DISK_VOLUME_NAMES disk names in the ZONES zone in the GCP_PROJECT_ID project. It re-attaches the disk volume after waiting for the duration specified by TOTAL_CHAOS_DURATION environment variable.
Note: DISK_VOLUME_NAMES environment variable contains multiple comma-separated disk names. The comma-separated zone names should be provided in the same order as the disk names.
Use the following example to tune it:
## details of the GCP disk
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
chaosServiceAccount: litmus-admin
experiments:
- name: gcp-vm-disk-loss
spec:
components:
env:
# comma separated list of disk volume names
- name: DISK_VOLUME_NAMES
value: 'disk-01,disk-02'
# comma separated list of zone names corresponds to the DISK_VOLUME_NAMES
# it should be provided in same order of DISK_VOLUME_NAMES
- name: ZONES
value: 'zone-01,zone-02'
# GCP project ID to which disk volume belongs
- name: GCP_PROJECT_ID
value: 'project-id'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'