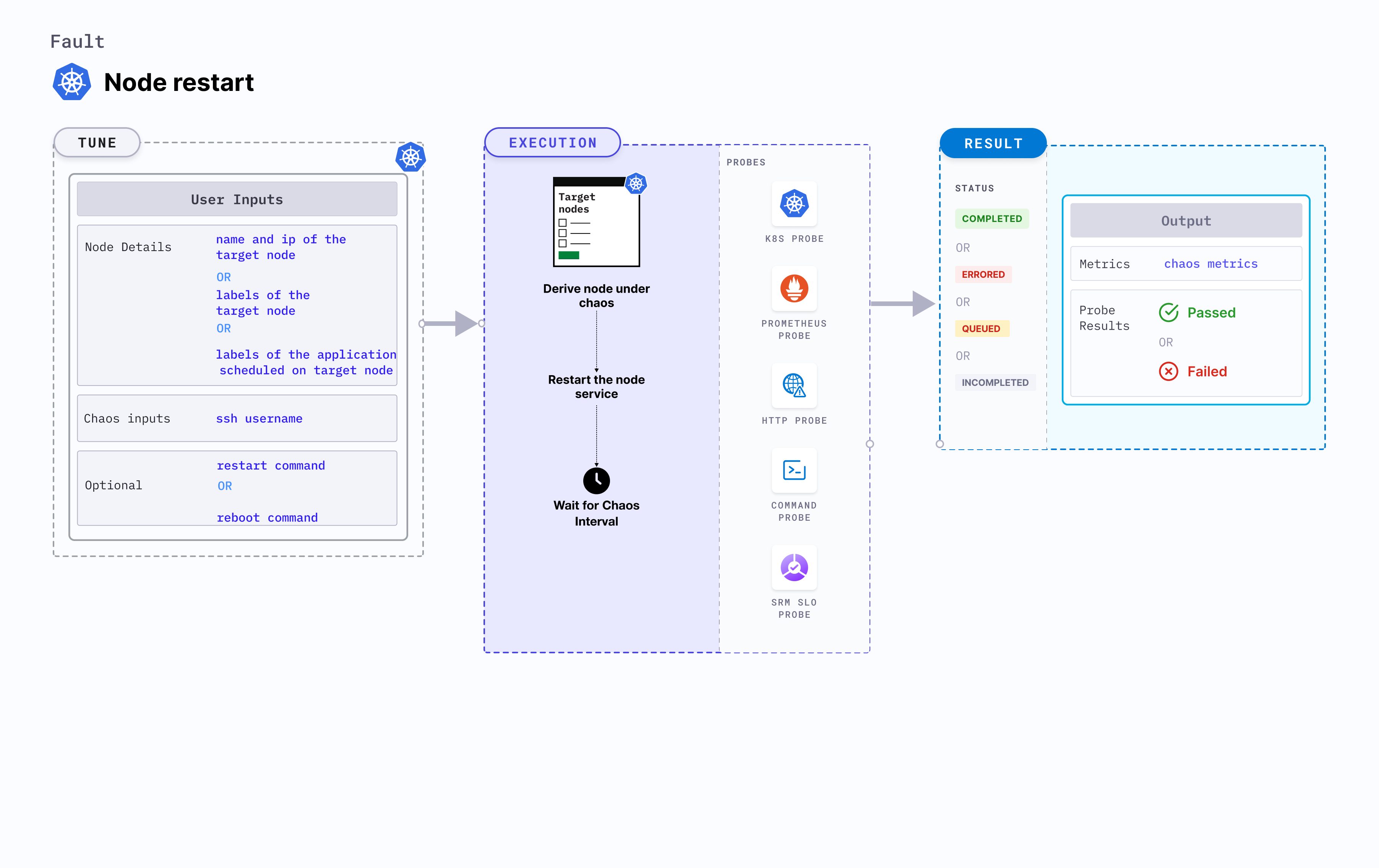
Node restart
Introduction
Node restart disrupts the state of the node by restarting it.
Use cases
- Node restart fault determines the deployment sanity (replica availability and uninterrupted service) and recovery workflows of the application pod in the event of an unexpected node restart.
- It simulates loss of critical services (or node-crash).
- It verifies resource budgeting on cluster nodes (whether request(or limit) settings honored on available nodes).
- It verifies whether topology constraints are adhered to (node selectors, tolerations, zone distribution, affinity or anti-affinity policies) or not.
Kubernetes > 1.16 is required to execute this fault.
Create a Kubernetes secret named
id-rsawhere the fault will be executed. The contents of the secret will be the private SSH key forSSH_USERthat will be used to connect to the node that hosts the target pod in the secret fieldssh-privatekey.Below is a sample secret file:
apiVersion: v1
kind: Secret
metadata:
name: id-rsa
type: kubernetes.io/ssh-auth
stringData:
ssh-privatekey: |-
# SSH private key for ssh contained hereCreating the RSA key pair for remote SSH access for those who are already familiar with an SSH client, has been summarized below.
- Create a new key pair and store the keys in a file named
my-id-rsa-keyandmy-id-rsa-key.pubfor the private and public keys respectively:
ssh-keygen -f ~/my-id-rsa-key -t rsa -b 4096- For each available node, run the below command that copies the public key of
my-id-rsa-key:
ssh-copy-id -i my-id-rsa-key user@nodeFor further details, refer to this documentation. After copying the public key to all nodes and creating the secret, you are all set to execute the fault.
- Create a new key pair and store the keys in a file named
The target nodes should be in the ready state before and after injecting chaos.
Fault tunables
Mandatory tunables
| Tunable | Description | Notes |
|---|---|---|
| TARGET_NODE | Name of the target node subject to chaos. If this is not provided, a random node is selected. | For more information, go to target node. |
| NODE_LABEL | It contains the node label that is used to filter the target nodes. | It is mutually exclusive with the TARGET_NODES environment variable. If both are provided, TARGET_NODES takes precedence. For more information, go to tagret node with labels. |
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| LIB_IMAGE | Image used to run the stress command. | Default: litmuschaos/go-runner:latest. For more information, go to image used by the helper pod. |
| SSH_USER | Name of the SSH user. | Default: root. For more information, go to SSH user. |
| TARGET_NODE_IP | Internal IP of the target node subject to chaos. If not provided, the fault uses the node IP of the TARGET_NODE. | Default: empty. For more information, go to target node internal IP. |
| REBOOT_COMMAND | Command used to reboot. | Default: sudo systemctl reboot. For more information, go to reboot command. |
| TOTAL_CHAOS_DURATION | Duration that you specify, through which chaos is injected into the target resource (in seconds). | Default: 120 s. For more information, go to duration of the chaos. |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30 s. For more information, go to ramp time. |
Reboot command
Command to restart the target node. Tune it by using the REBOOT_COMMAND environment variable.
The following YAML snippet illustrates the use of this environment variable:
# provide the reboot command
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-restart
spec:
components:
env:
# command used for the reboot
- name: REBOOT_COMMAND
value: 'sudo systemctl reboot'
# name of the target node
- name: TARGET_NODE
value: 'node01'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
SSH user
Name of the SSH user for the target node. Tune it by using the SSH_USER environment variable.
The following YAML snippet illustrates the use of this environment variable:
# name of the ssh user used to ssh into targeted node
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-restart
spec:
components:
env:
# name of the ssh user
- name: SSH_USER
value: 'root'
# name of the target node
- name: TARGET_NODE
value: 'node01'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
Target node internal IP
Internal IP of the target node (optional). If the internal IP is not provided, the fault derives the internal IP of the target node. Tune it by using the TARGET_NODE_IP environment variable.
The following YAML snippet illustrates the use of this environment variable:
# internal ip of the targeted node
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: node-restart
spec:
components:
env:
# internal ip of the targeted node
- name: TARGET_NODE_IP
value: '10.0.170.92'
# name of the target node
- name: TARGET_NODE
value: 'node01'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'