Pod autoscaler
Introduction
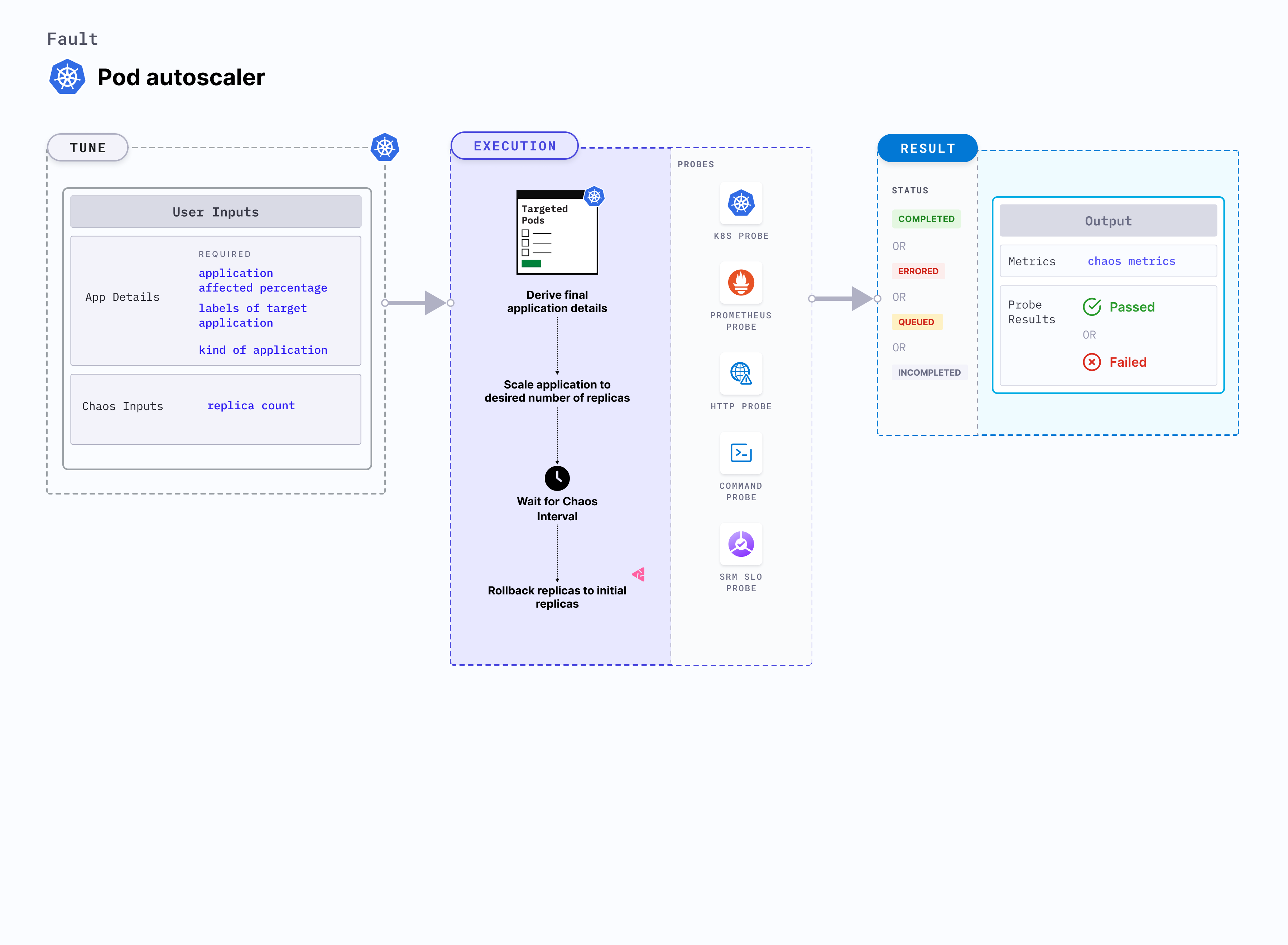
Pod autoscaler is a Kubernetes pod-level chaos fault that determines whether nodes can accomodate multiple replicas of a given application pod. This fault examines the node auto-scaling feature by determining whether the pods were successfully rescheduled within a specified time frame if the existing nodes are running at the specified limits.
Use cases
Pod autoscaler determines how an application accomodates multiple replicas of a given application pod at unexpected times.
note
- Kubernetes > 1.16 is required to execute this fault.
- The application pods should be in the running state before and after injecting chaos.
Fault tunables
Mandatory tunables
| Tunable | Description | Notes |
|---|---|---|
| REPLICA_COUNT | Number of replicas you wish to scale to. | nil. For more information, go to replica counts |
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| TOTAL_CHAOS_DURATION | Duration for which to insert chaos (in seconds). | Default: 60 s. For more information, go to duration of the chaos. |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30 s. For more information, go to ramp time |
Replica counts
Number of replicas that need to be present in the target application during chaos. Tune it by using the REPLICA_COUNT environment variable.
The following YAML snippet illustrates the use of this environment variable:
# provide the number of replicas
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "default"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-admin
experiments:
- name: pod-autoscaler
spec:
components:
env:
# number of replica, needs to scale
- name: REPLICA_COUNT
value: "3"
- name: TOTAL_CHAOS_DURATION
VALUE: "60"