Elasticsearch
Harness Continuous Verification (CV) integrates with Elasticsearch to:
- Verify that the deployed service is running safely and performing automatic rollbacks.
- Apply machine learning to every deployment to identify and flag anomalies in future deployments.
This topic describes how to set up an Elasticsearch health source when adding a CV step to your Continuous Deployment (CD).
Harness only supports the Lucene query language.
Use the Java-supported format when specifying dates in a query.
Prerequisite
Elasticsearch is added as a verification provider in Harness.
Set up continuous verification
To set up CV, you need to configure a Service Reliability Management (SRM)-monitored service. A monitored service is a mapping of a Harness service to a service that is being monitored by your Application Performance Monitoring (APM) or logging tool.
Add Verify Step
To add a Verify step to your pipeline, use one of the methods below.
Add a Verify step while building a deployment stage
If you're building a deployment stage and currently on the Execution Strategies page:
Select the Enable Verification option.
The Verify step gets added to the pipeline.
Select the Verify step.
The Verify settings page appears.
Add a Verify step to an existing deployment stage
If you already have a deployment stage:
Select the stage where you want to add the Verify step.
On the stage settings pane, select the Execution tab.
On the pipeline, hover over where you want the Verify step, select the + icon, and then choose Add Step.
The Step Library page appears. You can add a step at various points in the pipeline such as the beginning, end, in between existing steps, or below an existing step. Simply choose the location where you want to add the step and follow the prompts to add it.
In the Continuous Verification section, select Verify.
The Verify settings page appears.
Define name and time out information
In Name, enter a name for the Verification step.
In Timeout, enter a timeout value for the step. Harness uses this information to time out the verification. Use the following syntax to define timeout:
- w for weeks. For example, to define one week, enter 1w.
- d for days. For example, to define 7 days, enter 7d.
- h for hours. For example, to define 24 hours, enter 24h.
- m for minutes, For example, to define 100 minutes, enter 100m.
- s for seconds. For example, to define 500 seconds, enter 500s.
- ms for milliseconds. For example, to define 1000 milliseconds, enter 1000ms.
The maximum timeout value you can set is 53w. You can also set timeouts at the pipeline level.
Node filtering
Currently, this feature is behind the feature flag CV_UI_DISPLAY_NODE_REGEX_FILTER. Contact Harness Support to enable the feature.
This feature allows you to be more specific in node filtering by using Kubernetes PodName as a label. You can make analysis more explicit by telling CV which nodes to filter on. Just specify the filters on the control nodes (nodes that test nodes are compared against) and the test nodes (nodes CV checks).
To filter the nodes:
Expand Optional.
Choose Control Nodes and Test Nodes that Harness CV should focus on during analysis. You can either type a node’s name or use a simple pattern (Regex) to define the nodes you want to filter.
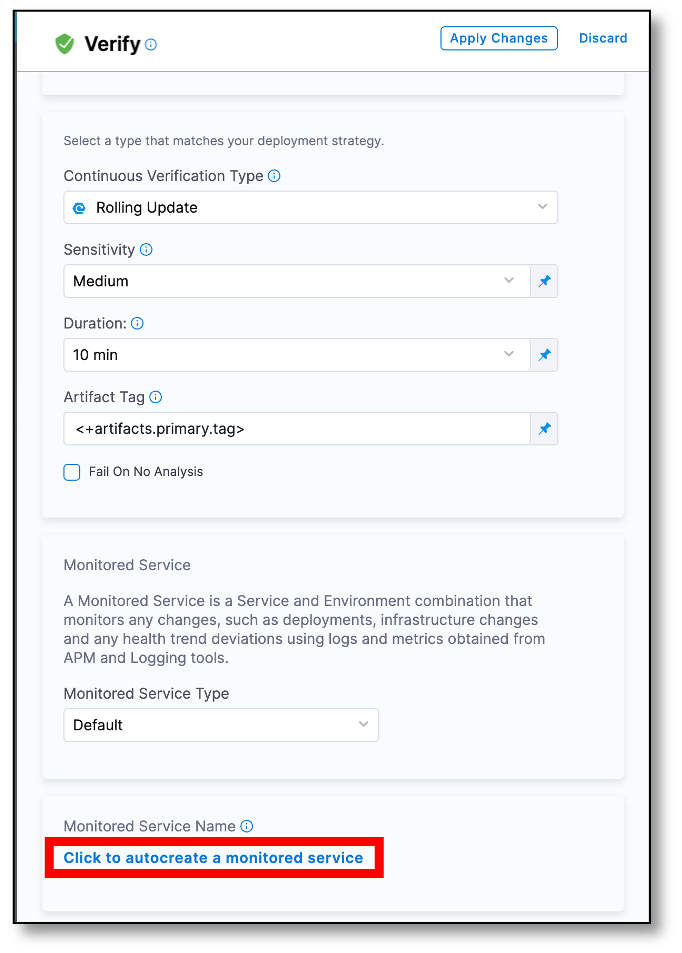
Select a continuous verification type, sensitivity, and duration
- In Continuous Verification Type, select a type that matches your deployment strategy. The following options are available:
- Auto: Harness automatically selects the best continuous verification type based on the deployment strategy.
- Rolling Update: Rolling deployment is a deployment technique that gradually replaces old versions of a service with a new version by replacing the infrastructure on which the service runs. Rolling updates are useful in situations where a sudden changeover might cause downtime or errors.
- Canary: Canary deployment involves a two-phased deployment. In phase one, new pods and instances with the new service version are added to a single environment. In phase two, a rolling update is performed in the same environment. Canary deployment helps to detect issues with the new deployment before fully deploying it.
- Blue Green: Blue-green deployment is a technique used to deploy services to a production environment by gradually shifting user traffic from an old version to a new one. The previous version is referred to as the blue environment, while the new version is known as the green environment. Upon completion of the transfer, the blue environment remains on standby in case of a need for rollback or can be removed from production and updated to serve as the template for future updates.
- Load Test: Load testing is a strategy used in lower-level environments, such as quality assurance, where a consistent load is absent and deployment validation is typically accomplished through the execution of load-generating scripts. This is useful to ensure that the application can handle the expected load and validate that the deployment is working as expected before releasing it to the production environment. When you choose "Load Test," you must also choose one of these options:Set successful verification as a baseline for load testing
- **Last Successful Job Run**: Compare the test data with the data from the previous successful verification.
- In Sensitivity, choose the sensitivity level. The available options are High, Medium, and Low. When the sensitivity is set to high, even minor anomalies are treated as verification failures. When the sensitivity is set to High, any anomaly, no matter how small, will be treated as a verification failure. This ensures that even the slightest issue is detected and addressed before releasing the deployment to production.
- In Duration, choose a duration. Harness will use the data points within this duration for analysis. For instance, if you select 10 minutes, Harness will analyze the first 10 minutes of your log or APM data. It is recommended to choose 10 minutes for logging providers and 15 minutes for APM and infrastructure providers. This helps you thoroughly analyze and detect issues before releasing the deployment to production.
- In the Artifact Tag field, reference the primary artifact that you added in the Artifacts section of the Service tab. Use the Harness expression
<+serviceConfig.artifacts.primary.tag>to reference this primary artifact. To learn about artifact expression, go to Harness expression. - Select Fail On No Analysis if you want the pipeline to fail if there is no data from the health source. This ensures that the deployment fails when there is no data for Harness to analyze.
Create a monitored service
Harness Continuous Verification monitors the health trend deviations using logs and metrics obtained from the health source, such as APM and logging tools, via a monitored service.
To create a monitored service:
In the Monitored Service Name section, select Click to autocreate a monitored service.
Harness automatically generates a monitored service name by combining the service and environment names. The generated name appears in the Monitored Service Name field. Note that you cannot edit the monitored service name.
If a monitored service with the same name and environment already exists, the Click to autocreate a monitored service option is hidden and the existing monitored service is assigned to the Verify step by Harness.
If you've set up a service or environment as runtime values, the auto-create option for monitored services won't be available. When you run the pipeline, Harness combines the service and environment values to create a monitored service. If a monitored service with the same name already exists, it will be assigned to the pipeline. If not, Harness skips the Verification step.
For instance, if you input the service as todolist and the environment as dev, Harness creates a monitored service with the name todolist_dev. If a monitored service with that name exists, Harness assigns it to the pipeline. If not, Harness skips the Verification step.
Add a health source
A health source is an APM or logging tool that monitors and aggregates data in your deployment environment.
Define health source
To add a health source:
In the Health Sources section, select + Add New Health Source.
The Add New Health Source dialog appears.
On the Define Health Source tab, do the following:
In the Define Health Source section, select ElasticSearch as health source type.
In the Health Source Name field, enter a name for the health source.
In the Connect Health Source section, select Select Connector.
The Create or Select an Existing Connector dialog appears.Select a connector for the Elasticsearch health source and then select Apply Selected.
The selected connector appears in the Select Connector dropdown.Select Next.
The Configuration tab appears.
Currently, Harness supports only Elasticsearch logs. The ElasticSearch Logs option is selected by default in the Select Feature field.
Define log configuration settings
On the Configuration tab, select + Add Query.
The Add Query dialog appears.
Enter a name for the query and then select Submit.
The query that you added gets listed under the Logs Group. The Custom Queries settings are displayed. These settings help you retrieve the desired logs from the Elasticsearch platform and map them to the Harness service.
Define a query
In the Query Specifications and Mapping section, select a log index from the Log Indexes list.
In the Query field, enter a log query and select Run Query to execute it.
A sample record in the Records field. This helps you confirm the accuracy of the query you've constructed.
In the Field Mapping section, map the following identifiers to select the data that you want to be displayed from the logs.
- Timestamp Identifier
- Service Instance Identifier
- Message Identifier
- Timestamp Format
To define mapping, in each identifier field, do the following:
Select +.
The Select path for Service Instance Identifier page appears.
Go to the identifier value that you want to map and choose Select.
The selected value gets mapped to the corresponding identifier field.
Select Get sample log messages.
Sample logs are displayed that help you verify if the query you built is correct.
Save the health source settings
- After configuring all the settings, select Submit to add the health source to the Verify step.
- Select Apply Changes to save the changes made to the Verify step.
Run the pipeline
To run the pipeline:
In the upper-right corner, select Run.
The Run Pipeline dialog box appears.
In the dialog box, do the following:
- Tag: If you did not add a tag in the Artifact Details settings, select it now.
- Skip preflight check: Select this option if you want to skip the preflight check.
- Notify only me about execution status: Select this option if you want Harness to alert only you about the execution status.
Select Run Pipeline.
The pipeline starts running.
View results
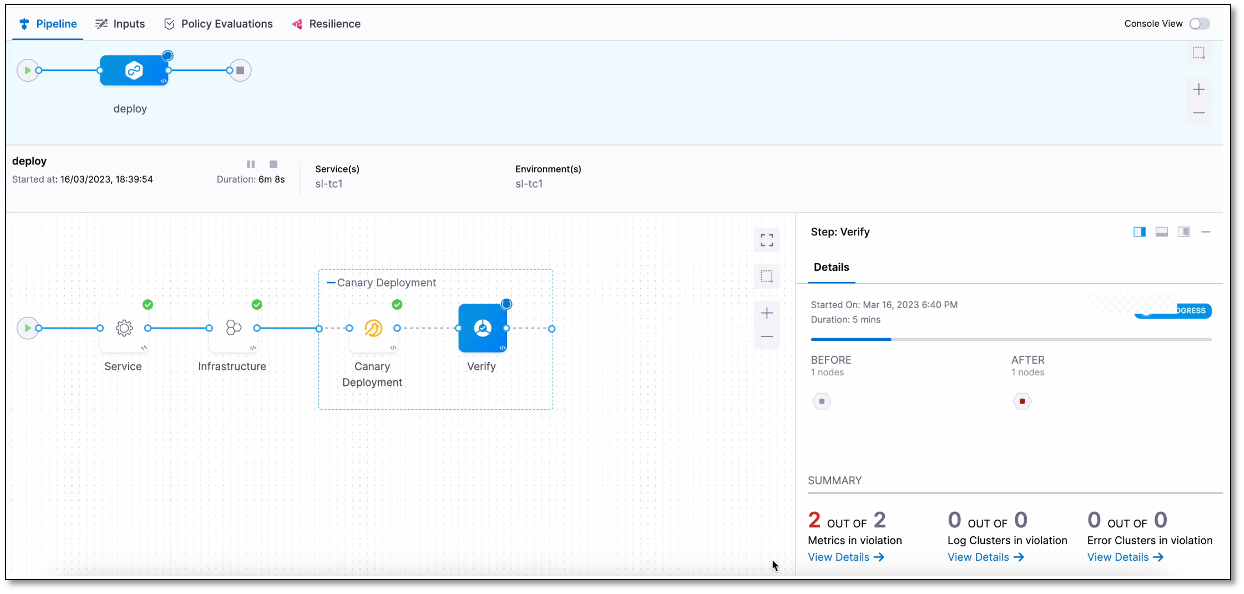
The Summary section displays the following details when the Verify step begins:
- Metrics in violation
- Log Clusters in violation
- Error Clusters in violation
Note that it may take some time for the analysis to begin. The screenshot below shows a Verification step running in a deployment:
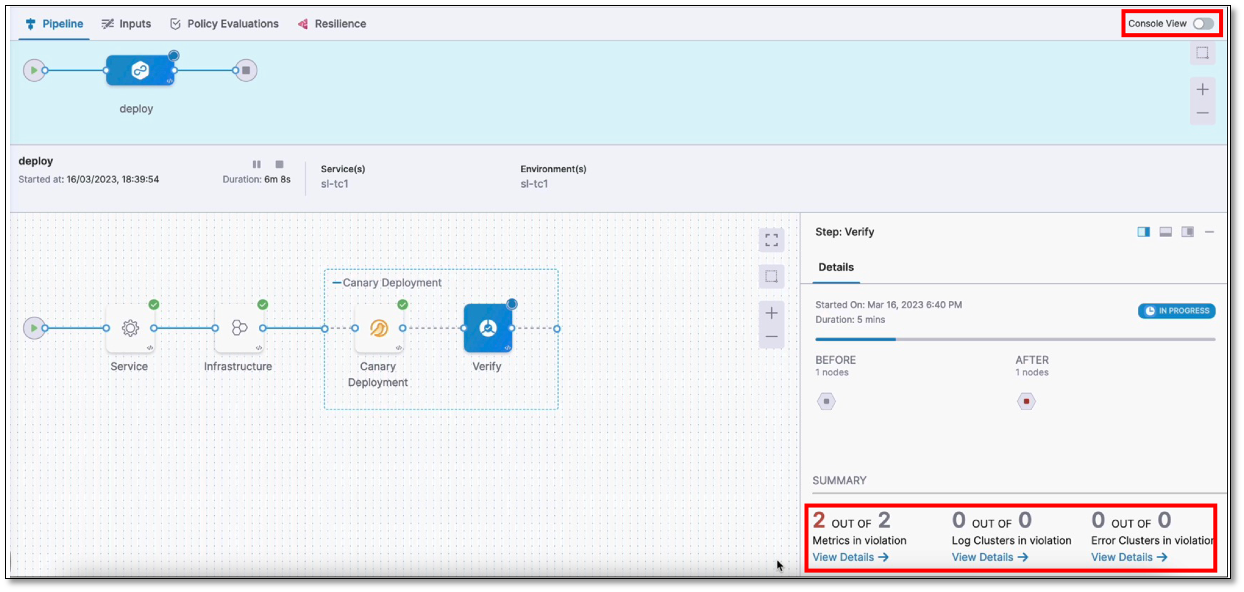
Console view
The console view displays detailed logs of the pipeline, including verification logs. To view the console, select View Details in the Summary section or turn on the Console View toggle switch in the upper-right corner.
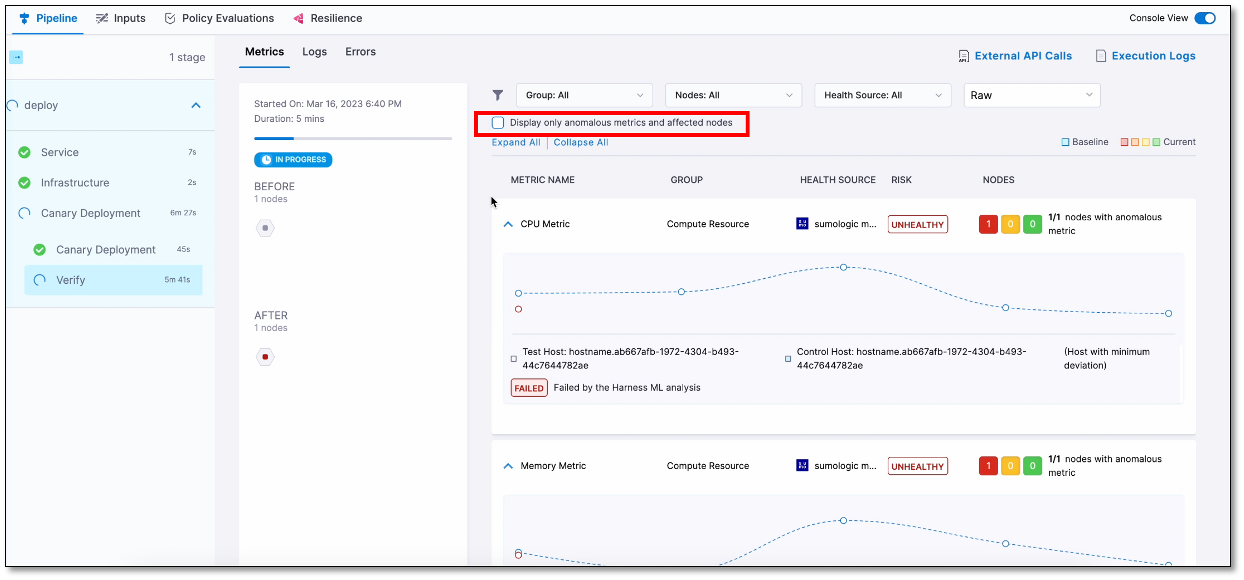
By default, the console displays logs of only the anomalous metrics and affected nodes. To see all logs, clear the Display only anomalous metrics and affected nodes check box.
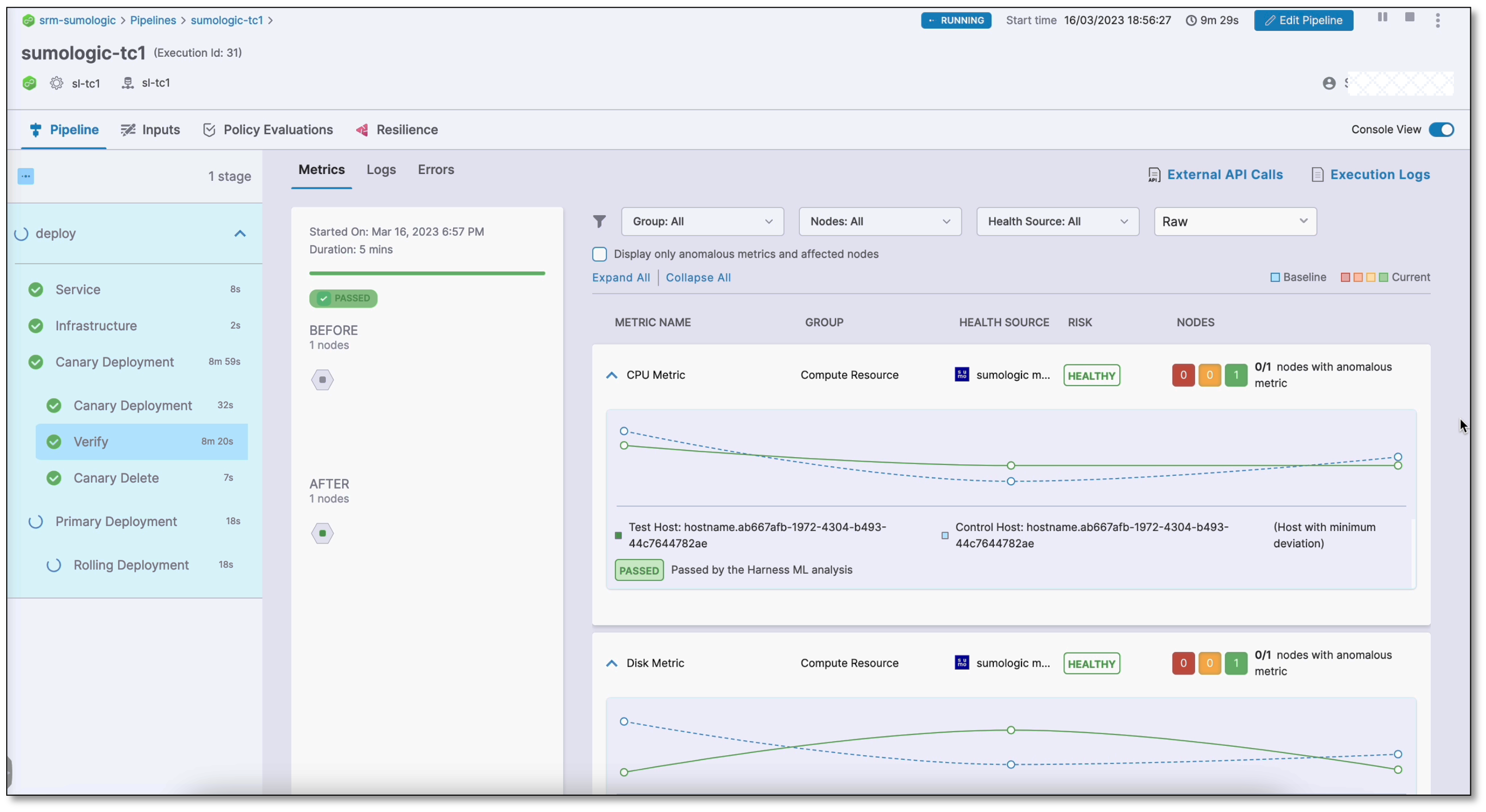
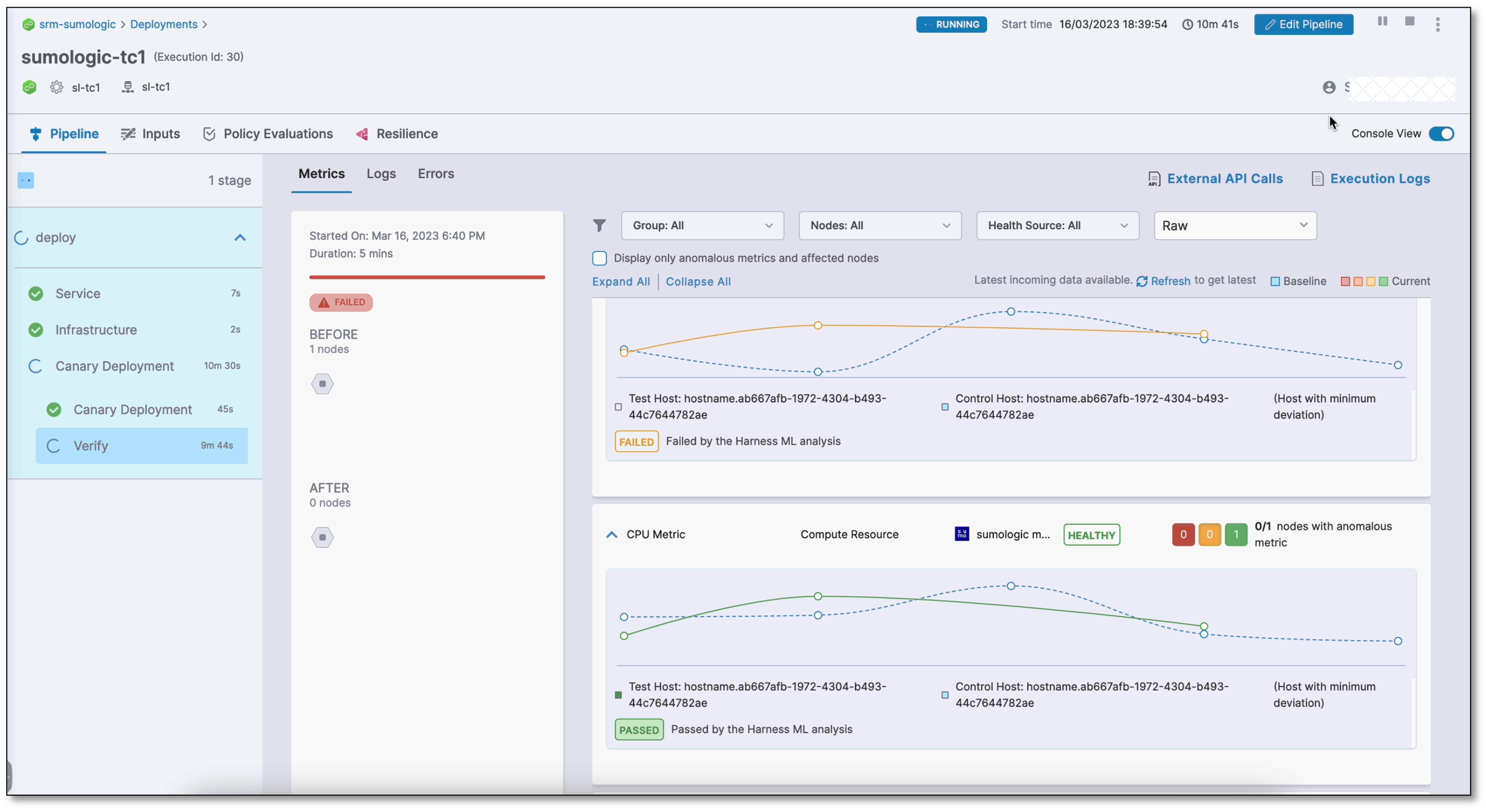
The following screenshots show successful and failed verifications in a deployment run:
Successful verification
Failed verification
Set a pinned baseline
Currently, this feature is behind the feature flag SRM_ENABLE_BASELINE_BASED_VERIFICATION. Contact Harness Support to enable the feature.
You can set specific verification in a successful pipeline execution as a baseline. This is available with Load Testing as the verification type.
Set successful verification as a baseline
To set a verification as baseline for future verifications:
In Harness, go to Deployments, select Pipelines, and find the pipeline you want to use as the baseline.
Select the successful pipeline execution with the verification that you want to use as the baseline.
The pipeline execution is displayed.
On the pipeline execution, navigate to the Verify section, and then select Pin baseline.
The selected verification is now set as the baseline for future verifications.
Replace an existing pinned baseline
To use a new baseline from a pipeline and replace the existing pinned baseline, follow these steps:
In Harness, go to Deployments, select Pipelines, and find the pipeline from which you want to remove the baseline.
Select the successful pipeline execution with the verification that you have previously pinned as the baseline.
On the pipeline execution, navigate to the Verify section, and then select Pin baseline.
A confirmation alert message appears, asking if you want to replace the existing pinned baseline with the current verification. After you confirm, the existing pinned baseline gets replaced with the current verification.