Checkmarx scanner reference
You can scan your repositories using Checkmarx. Harness STO supports the following workflows:
- Ingestion workflows for all Checkmarx One services (including SAST and SCA) that can publish scan results in SARIF format.
- Orchestration, Extraction, and Ingestion workflows for Checkmarx SAST and Checkmarx SCA scans.
Before you begin
Docker-in-Docker requirements
Docker-in-Docker is not required for ingestion workflows where the scan data has already been generated.
You need to include a Docker-in-Docker background service in your stage if either of these conditions apply:
- You configured your scanner using a generic Security step rather than a scanner-specific template such as Aqua Trivy, Bandit, Mend, Snyk, etc.
- You’re scanning a container image using an Orchestration or Extraction workflow.
Set up a Docker-in-Docker background step
Go to the stage where you want to run the scan.
In Overview, add the shared path
/var/run.In Execution, do the following:
- Click Add Step and then choose Background.
- Configure the Background step as follows:
- Dependency Name =
dind - Container Registry = The Docker connector to download the DinD image. If you don't have one defined, go to Docker connector settings reference.
- Image =
docker:dind - Under Optional Configuration, select the Privileged checkbox.
- Dependency Name =
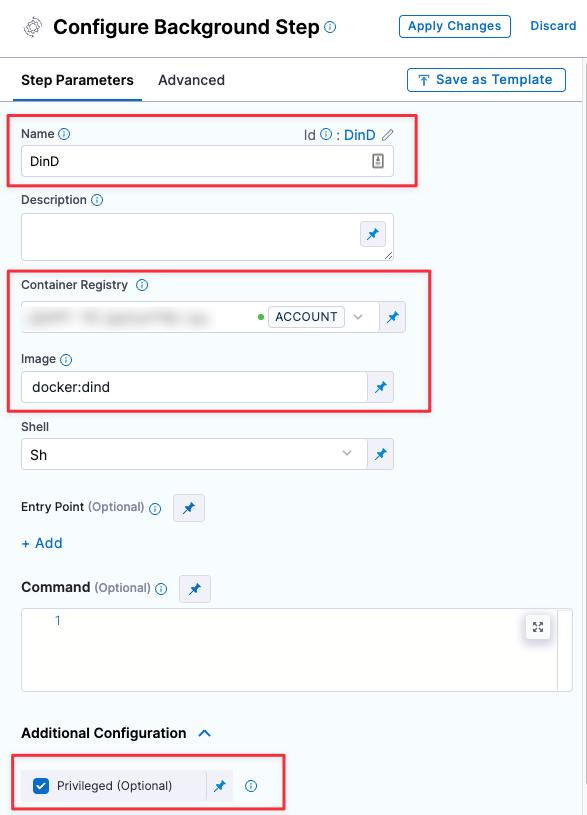
Root access requirements
You need to run the scan step with root access if either of the following apply:
You need to run a Docker-in-Docker background service.
You need to add trusted certificates to your scan images at runtime.
You can set up your STO scan images and pipelines to run scans as non-root and establish trust for your own proxies using self-signed certificates. For more information, go to Configure STO to Download Images from a Private Registry.
Checkmarx step configuration
The recommended workflow is add a Checkmarx step to a Security Tests or CI Build stage and then configure it as described below. You can also configure Checkmarx scans programmatically by copying, pasting, and editing the YAML definition.
- UI configuration support is currently limited to a subset of scanners. Extending UI support to additional scanners is on the Harness engineering roadmap.
- Each scanner template shows only the options that apply to a specific scan. If you're setting up a repository scan, for example, the UI won't show Container Image settings.
- Docker-in-Docker is not required for these steps unless you're scanning a container image. If you're scanning a repository using Bandit, for example, you don't need to set up a Background step running DinD.
- Support is currently limited to Kubernetes and Harness Cloud AMD64 build infrastructures only.
Scanner Template example
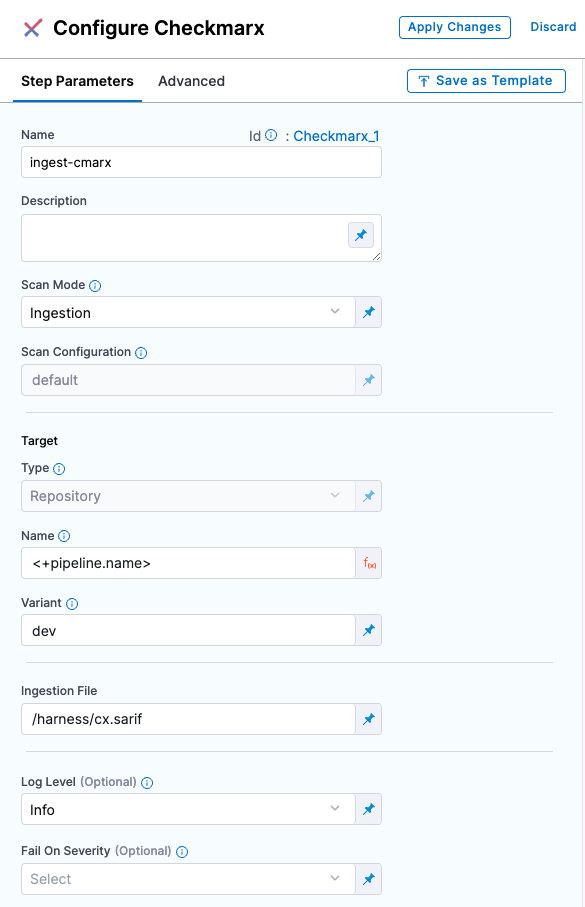
Scan settings
Scan Mode
The orchestration mode to use for the scan. The following list includes the UI and YAML values for the supported options.
- Orchestrated A fully-orchestrated scan. A Security step in the Harness pipeline orchestrates a scan and then normalizes and compresses the results.
- Extraction A partially-orchestrated scan. The Security step pulls scan results from an external SaaS service and then normalizes and compresses the data.
- Ingestion Ingestion scans are not orchestrated. The Security step ingest results from a previous scan (for a scan run in an previous step) and then normallizes and compresses the results.
Scan Configuration
The predefined configuration to use for the scan. All scan steps have at least one configuration.
Target
Type
- Repository Scan a codebase repo.
Name
The Identifier that you want to assign to the target you’re scanning in the pipeline. Use a unique, descriptive name such as codebaseAlpha or jsmith/myalphaservice. Using descriptive target names will make it much easier to navigate your scan data in the STO UI.
Variant
An identifier for a specific variant to scan, such as the branch name or image tag. This identifier is used to differentiate or group results for a target. Harness maintains a historical trend for each variant.
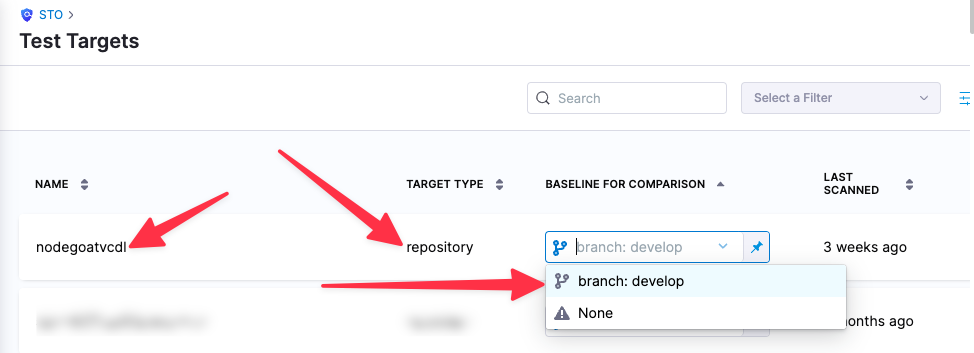
You can see the target name, type, and variant in the Test Targets UI:
Workspace
The workspace path on the pod running the Security step. The workspace path is /harness by default.
You can override this if you want to scan only a subset of the workspace. For example, suppose the pipeline publishes artifacts to a subfolder /tmp/artifacts and you want to scan these artifacts only. In this case, you can specify the workspace path as /harness/tmp/artifacts.
Ingestion File
The results data file to use when running an Ingestion scan. STO steps can ingest scan data in SARIF and Harness Custom JSON format. Generally an Ingestion scan consists of a scan step (to generate the data file) and an ingestion step (to ingest the data file).
Authentication
Domain
The fully-qualified URL to the scanner.
Enforce SSL
The step and the scanner communicate over SSL by default. Set this to false to disable SSL (not safe).
Access ID
Username to log in to the scanner.
Access Token
The access token to log in to the scanner. In most cases this is a password or an API key.
You should create a Harness text secret with your encrypted token and reference the secret using the format <+secrets.getValue("project.container-access-id")>. For more information, go to Add and Reference Text Secrets.
Scan Tool
Team Name
The Checkmarx team name. Use the format /<server-name>/<team-name> — for example, /server1.myorg.org/devOpsEast.
Project Name
The name of the scan project as defined in the scanner. This is the also the target name in the Harness UI (Security Tests > Test Targets).
Log Level, CLI flags, and Fail on Severity
Log Level
The minimum severity of the messages you want to include in your scan logs. You can specify one of the following:
- DEBUG
- INFO
- WARNING
- ERROR
Additional CLI flags
You can use this field to run the Checkmarx plugin with specific command-line arguments. To run an incremental scan, for example, specify tool_args = -incremental.
Running incremental scans with Checkmarx
In some cases, you might want to run an incremental rather than a full scan with Checkmarx due to time or licensing limits. An incremental scan evaluates only new or changed code in a merge or pull request. Incremental scans are faster than full scans, but become less accurate over time.
Consider carefully when to run incremental vs. full scans. See When should I use Incremental Scans vs Full Scans in CxSAST? in the Checkmarx documentation.
Fail on Severity
Every Security step has a Fail on Severity setting. If the scan finds any vulnerability with the specified severity level or higher, the pipeline fails automatically. You can specify one of the following:
CRITICALHIGHMEDIUMLOWINFONONE— Do not fail on severity
The YAML definition looks like this: fail_on_severity : critical # | high | medium | low | info | none
Settings
You can use this field to provide environment variables to be used during the execution of the step. As an exemple, if you need to access your Checkmarx server through a proxy, you can add this setting:
- key =
JAVA_TOOL_OPTIONS - value =
-DproxySet=true -Dhttp.proxyHost=MY_PROXY_ADDRESS -Dhttp.proxyPort=MY_PROXY_PORT
Replace MY_PROXY_ADDRESS with your proxy address or proxy FQDN, and MY_PROXY_PORT with your proxy port.
If you want to go through an HTTPS proxy, replace -Dhttp with -Dhttps.
Additional Configuration
In the Additional Configuration settings, you can use the following options:
Advanced settings
In the Advanced settings, you can use the following options:
Security step configuration (deprecated)
You can set up any supported scanner using a Security step: create a CI Build or Security Tests stage, add a Security step, and then add the setting:value pairs as specified below.
Target and variant
The following settings are required for every Security step:
target_nameA user-defined label for the code repository, container, application, or configuration to scan.variantA user-defined label for the branch, tag, or other target variant to scan.
Make sure that you give unique, descriptive names for the target and variant. This makes navigating your scan results in the STO UI much easier.
You can see the target name, type, and variant in the Test Targets UI:
For more information, go to Targets, baselines, and variants in STO.
Checkmarx scan settings
product_name=checkmarxscan_type=repositorypolicy_type=orchestratedScan,dataLoad, oringestionOnly- When
policy_typeis set toorchestratedScanordataLoad:product_domainproduct_access_idproduct_access_token= The account passwordproduct_team_name=/<server-name>/<team-name>for example,/server1.myorg.org/devOpsEastproduct_project_name
product_config_name=default- When
policy_typeis set toorchestratedScan fail_on_severity- See Fail on Severity.
tool_argsYou can use this field to run the Checkmarx plugin with specific command-line arguments. To run an incremental scan, for example, specifytool_args=-incremental. For more information, go to Running incremental scans with Checkmarx.
Ingestion file
The following setting is required for Security steps where the policy_type is ingestionOnly.
ingestion_fileThe results data file to use when running an Ingestion scan. You should specify the full path to the data file in your workspace, such as/shared/customer_artifacts/my_scan_results.json. STO steps can ingest scan data in SARIF and Harness Custom JSON format.
The following steps outline the general workflow for ingesting scan data into your pipeline:
Specify a shared folder for your scan results, such as
/shared/customer_artifacts. You can do this in the Overview tab of the Security stage where you're ingesting your data.Create a Run step that copies your scan results to the shared folder. You can run your scan externally, before you run the build, or set up the Run step to run the scan and then copy the results.
Add a Security step after the Run step and add the
target name,variant, andingestion_filesettings as described above.
For a complete workflow description and example, go to Ingest Scan Results into an STO Pipeline.
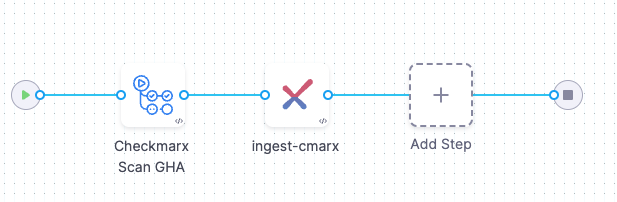
Example workflow: Ingest SARIF data from a Checkmarx GitHub Action scan
The following pipeline example illustrates an ingestion workflow. It consists of two steps:
- An Action step scans a code repo using a Checkmarx GitHub Action and export the scan results to a SARIF data file.
- A Checkmarx step that ingests the SARIF data.
pipeline:
projectIdentifier: STO
orgIdentifier: default
tags: {}
properties:
ci:
codebase:
connectorRef: NodeGoat_Harness_Hosted
repoName: https://github.com/OWASP/NodeGoat
build: <+input>
stages:
- stage:
name: CheckmarxSCA
identifier: checkmarxone
type: CI
spec:
cloneCodebase: true
execution:
steps:
- step:
type: Action
name: Checkmarx Scan GHA
identifier: CxFlow
spec:
uses: checkmarx-ts/checkmarx-cxflow-github-action@v1.6
with:
project: SampleProject
team: /CxServer/nzsouth
scanners: sca
checkmarx_url: <+secrets.getValue("my-checkmarx-url")>
checkmarx_username: zeronorth
checkmarx_password: <+secrets.getValue("my-checkmarx-password")>
checkmarx_client_secret: <+secrets.getValue("my-checkmarx-client-secret")>
sca_username: harness
sca_password: <+secrets.getValue("my-sca-passeword")>
sca_tenant: cxIntegrations
break_build: false
- step:
type: Checkmarx
name: ingest-cmarx
identifier: Checkmarx_1
spec:
mode: ingestion
config: default
target:
name: <+pipeline.name>
type: repository
variant: dev
advanced:
log:
level: debug
runAsUser: "1001"
ingestion:
file: /harness/cx.sarif
platform:
os: Linux
arch: Amd64
runtime:
type: Cloud
spec: {}
sharedPaths:
- /shared/customer_artifacts/
identifier: CheckmarxGitAction
name: CheckmarxGitAction