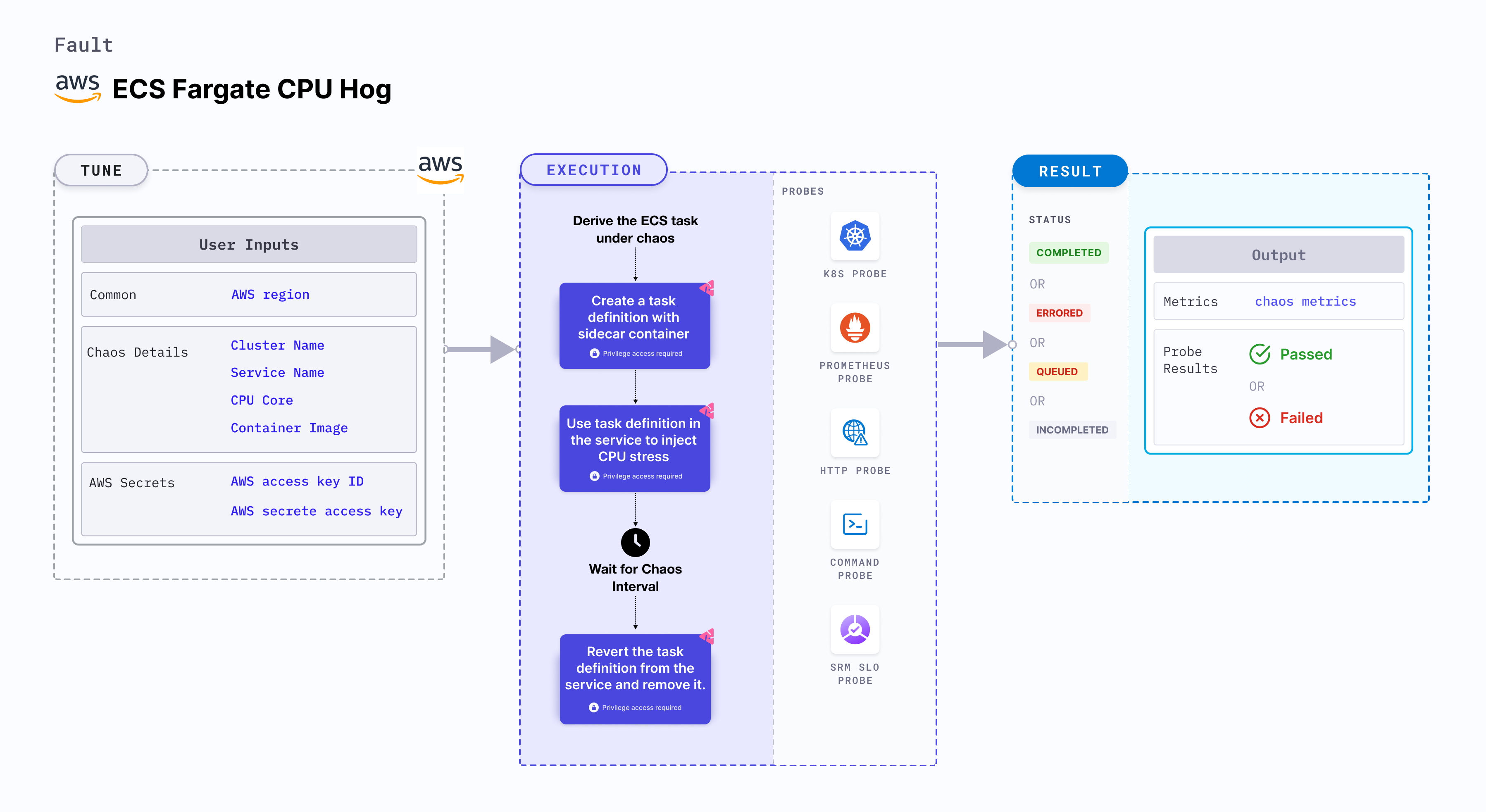
ECS Fargate CPU Hog
The ECS Fargate CPU Hog experiment enables you to intentionally increase the CPU usage of an ECS task container for a defined period, allowing you to assess and test the container's performance under high CPU utilization conditions or latency caused due to it.
Use cases
- Tests the behavior of your ECS tasks subjected to CPU stress, and validates the resilience and performance of your ECS tasks during the stress.
- Involves employing a sidecar container to augment the CPU utilization of an ECS task, which may result in latency issues impacting the performance of the main container.
- Validates the behavior of your application and infrastructure during a heavy CPU load, such as:
- Testing the resilience of your system during stress, including verifying if the latency of the main container is increased and if the container fail to survive.
Prerequisites
- Kubernetes >= 1.17
- ECS cluster running with the desired tasks and containers and familiarity with ECS service update and deployment concepts.
- Create a Kubernetes secret that has the AWS access configuration(key) in the
CHAOS_NAMESPACE. Below is a sample secret file:
apiVersion: v1
kind: Secret
metadata:
name: cloud-secret
type: Opaque
stringData:
cloud_config.yml: |-
# Add the cloud AWS credentials respectively
[default]
aws_access_key_id = XXXXXXXXXXXXXXXXXXX
aws_secret_access_key = XXXXXXXXXXXXXXX
It is recommended to use the same secret name, that is, cloud-secret. Otherwise, you will need to update the AWS_SHARED_CREDENTIALS_FILE environment variable in the fault template and you may be unable to use the default health check probes.
Permissions required
Here is an example AWS policy to execute the fault.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecs:DescribeTasks",
"ecs:DescribeServices",
"ecs:DescribeTaskDefinition",
"ecs:RegisterTaskDefinition",
"ecs:UpdateService",
"ecs:ListTasks",
"ecs:DeregisterTaskDefinition"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"iam:PassRole"
],
"Resource": "*"
}
]
}
- Refer to AWS named profile for chaos to know how to use a different profile for AWS faults.
- The ECS containers should be in a healthy state before and after introducing chaos. Refer to the common attributes and AWS-specific tunables to tune the common tunables for all faults and AWS-specific tunables.
- Refer to the superset permission/policy to execute all AWS faults.
Mandatory tunables
| Tunable | Description | Notes |
|---|---|---|
| CLUSTER_NAME | Name of the target ECS cluster | For example, cluster-1. |
| SERVICE_NAME | Name of the ECS service under chaos | For example, nginx-svc. |
| REGION | Region name of the target ECS cluster | For example, us-east-1. |
Optional tunables
| Tunable | Description | Notes |
|---|---|---|
| TOTAL_CHAOS_DURATION | Duration that you specify, through which chaos is injected into the target resource (in seconds) | Defaults to 30s. |
| CHAOS_INTERVAL | Interval between successive instance terminations (in seconds) | Defaults to 30s. |
| AWS_SHARED_CREDENTIALS_FILE | Path to the AWS secret credentials | Defaults to /tmp/cloud_config.yml. |
| CPU_CORE | Provide the CPU cores to stress the ECS task. | Default to '500' |
| CONTAINER_IMAGE | Provide stress image for the sidecar container. | Default to 'nginx' |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds) | For example, 30s. |
ECS Fargate CPU Hog
ECS Fargate CPU stress with a sepecified cores. Tune it by using the CPU_CORE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# Set container image for the target ECS task
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: aws-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: ecs-fargate-cpu-hog
spec:
components:
env:
- name: CPU_CORE
value: '2'
- name: REGION
value: 'us-east-2'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'
Stress Container Image
ECS Fargate CPU hog chaos with custom stress container image for sidecar container to inject chaos. Tune it by using the CONTAINER_IMAGE environment variable.
The following YAML snippet illustrates the use of this environment variable:
# Set container image for the target ECS task
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: aws-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: ecs-fargate-cpu-hog
spec:
components:
env:
- name: CONTAINER_IMAGE
value: 'chaosnative/go-runner:ci'
- name: CPU_CORE
value: '2'
- name: REGION
value: 'us-east-2'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'