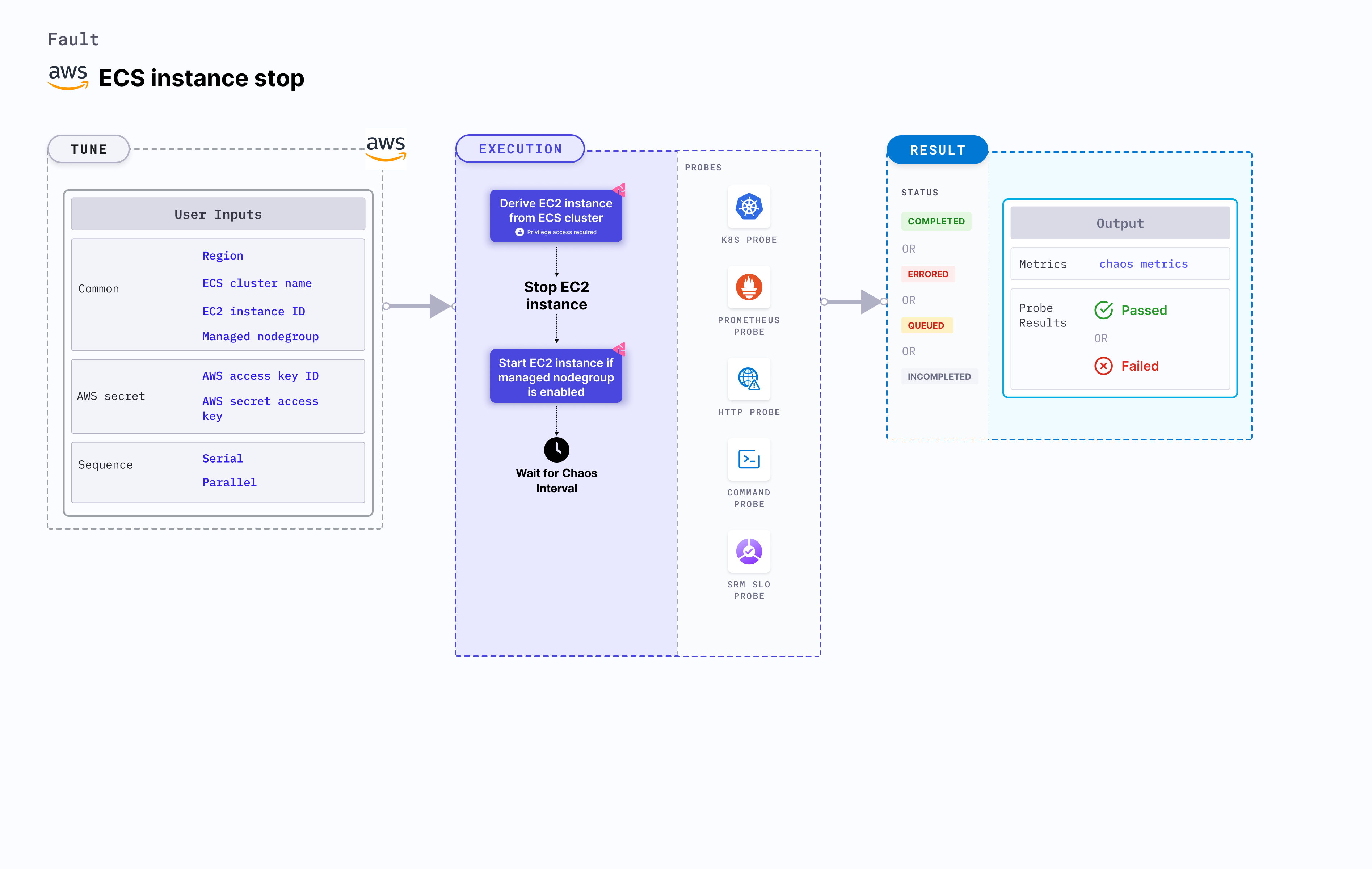
ECS instance stop
ECS instance stop induces stress on an AWS ECS cluster. It derives the instance under chaos from the ECS cluster.
- It causes EC2 instance to stop and get deleted from the ECS cluster for a specific duration.
Usage
View fault usage
Prerequisites
- Kubernetes >= 1.17
- Adequate AWS access to stop and start an EC2 instance.
- Create a Kubernetes secret that has the AWS access configuration(key) in the
CHAOS_NAMESPACE. Below is a sample secret file:
apiVersion: v1
kind: Secret
metadata:
name: cloud-secret
type: Opaque
stringData:
cloud_config.yml: |-
# Add the cloud AWS credentials respectively
[default]
aws_access_key_id = XXXXXXXXXXXXXXXXXXX
aws_secret_access_key = XXXXXXXXXXXXXXX
It is recommended to use the same secret name, i.e.
cloud-secret. Otherwise, you will need to update theAWS_SHARED_CREDENTIALS_FILEenvironment variable in the fault template and you may be unable to use the default health check probes.Refer to AWS Named Profile For Chaos to know how to use a different profile for AWS faults.
Permissions required
Here is an example AWS policy to execute the fault.
View policy for the fault
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ecs:ListContainerInstances",
"ecs:DescribeContainerInstances"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:StartInstances",
"ec2:StopInstances",
"ec2:DescribeInstanceStatus",
"ec2:DescribeInstances"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingInstances"
],
"Resource": "*"
}
]
}
Refer to the superset permission/policy to execute all AWS faults.
Default validations
The ECS container instance should be in a healthy state.
Fault tunables
Fault tunables
Mandatory fields
| Variables | Description | Notes |
|---|---|---|
| CLUSTER_NAME | Name of the target ECS cluster | For example, cluster-1 |
| REGION | The region name of the target ECS cluster | For example, us-east-1 |
Optional fields
| Variables | Description | Notes |
|---|---|---|
| TOTAL_CHAOS_DURATION | Duration that you specify, through which chaos is injected into the target resource (in seconds). | Defaults to 30s. |
| CHAOS_INTERVAL | The interval (in sec) between successive instance termination. | Defaults to 30s |
| AWS_SHARED_CREDENTIALS_FILE | Provide the path for aws secret credentials | Defaults to /tmp/cloud_config.yml |
| EC2_INSTANCE_ID | Provide the target instance ID from ECS cluster | If not provided will select randomly |
| SEQUENCE | It defines sequence of chaos execution for multiple instance | Defaults to parallel. Supports serial sequence as well. |
| RAMP_TIME | Period to wait before and after injecting chaos (in seconds). | For example, 30 |
Fault examples
Common and AWS-specific tunables
Refer to the common attributes and AWS-specific tunables to tune the common tunables for all faults and aws specific tunables.
ECS Instance Stop
It stops the instance of an ECS cluster for a certain chaos duration. We can provide the EC2 instance ID using EC2_INSTANCE_ID ENVs as well. If not provided it will select randomly.
Use the following example to tune it:
# stops the agent of an ECS cluster
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-admin
experiments:
- name: ecs-instance-stop
spec:
components:
env:
# provide the name of ECS cluster
- name: CLUSTER_NAME
value: 'demo'
- name: EC2_INSTANCE_ID
value: 'us-east-2'
- name: TOTAL_CHAOS_DURATION
VALUE: '60'